First, Understand What Snowflake Actually Is
Before you run a single SQL statement, it’s worth spending 5 minutes on architecture — because Snowflake is genuinely different from a traditional database, and understanding why will shape every decision you make.
The Three-Layer Separation
- Storage layer: Your data lives as compressed columnar files in cloud object storage (S3, Azure Blob, or GCS depending on your cloud provider). Snowflake manages this for you. You never touch the files directly.
- Compute layer (Virtual Warehouses): This is what runs your queries. A warehouse is a cluster of compute nodes that spins up on demand, runs your SQL, and then suspends when idle. You pay by the second, only when it’s running.
- Cloud services layer: Metadata management, query optimization, authentication, and access control all live here. This runs continuously but is included in your account — you don’t pay extra for it.
 Why This Matters for Real Teams
Why This Matters for Real Teams
The compute/storage separation means you can run multiple warehouses against the same data simultaneously — a data engineering warehouse loading new data, an analytics warehouse running reports, and a dashboard warehouse serving your BI tool — all without them competing for resources. This is architecturally impossible in traditional databases like MySQL or Postgres.
What I Noticed About the New Snowsight Interface
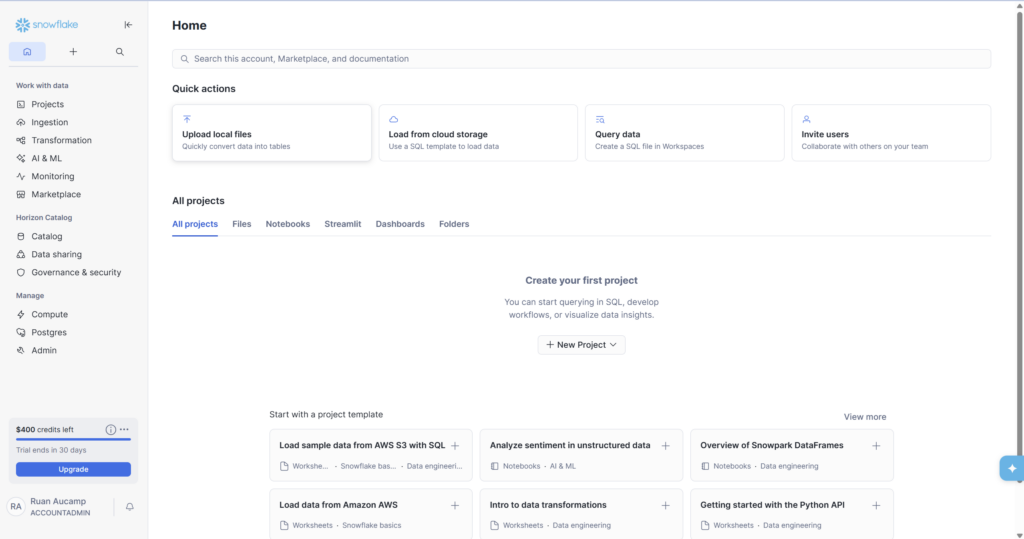
Snowflake recently upgraded its UI to Snowsight Horizon — and it’s a significant improvement. The Home screen (Screenshot 1) shows Quick Actions at the top for common tasks like uploading files and querying data, a Projects section for organizing your SQL files and notebooks, and $400 in trial credits with a 30-day countdown at the bottom left.
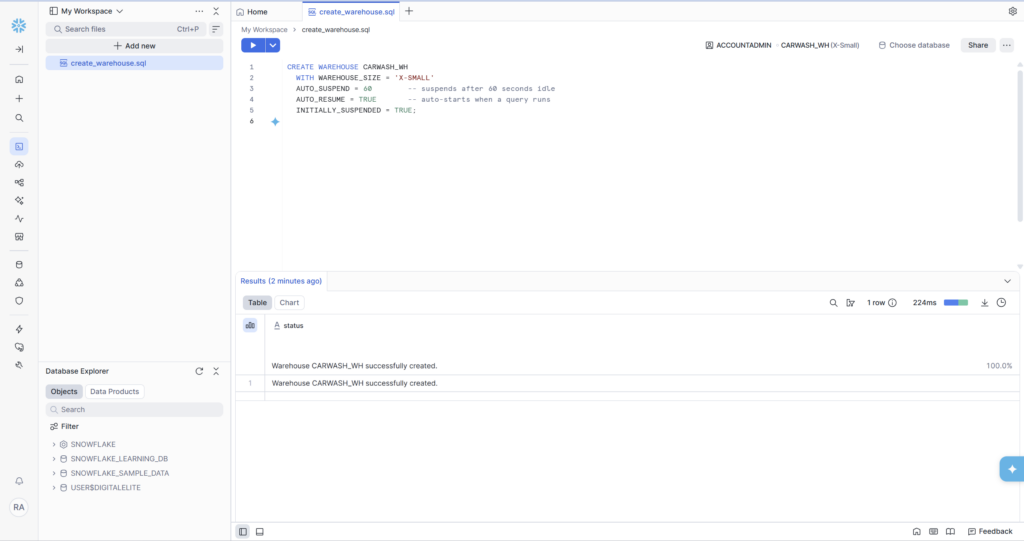
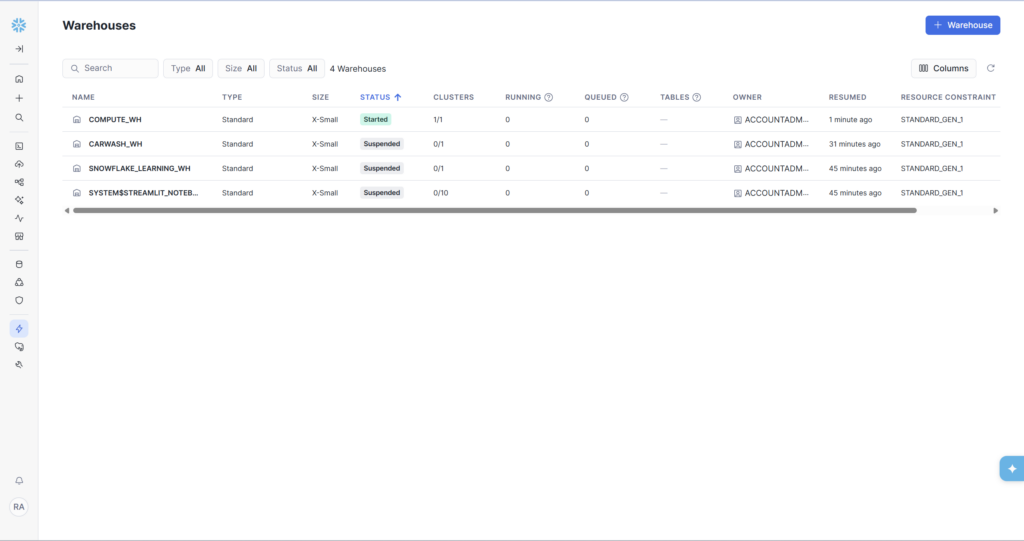
One thing worth noting: you’ll see a ‘COMPUTE_WH’ already exists in a fresh account. This is Snowflake’s default warehouse. We’re creating our own dedicated CARWASH_WH instead of using it — this is good practice for keeping project resources cleanly separated.
What We Built — Phase 1 Complete
In about 30 minutes, we went from a blank Snowflake trial account to a properly structured data warehouse environment. Here’s the full inventory:
 Phase 1 Deliverables — All Complete
Phase 1 Deliverables — All Complete
- CARWASH_WH — X-Small warehouse, auto-suspend 60s, auto-resume
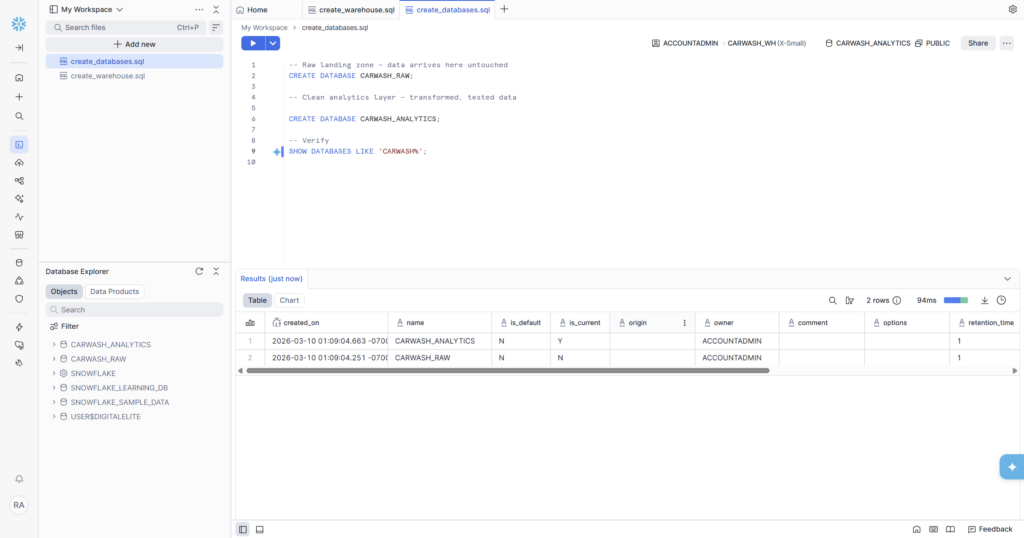
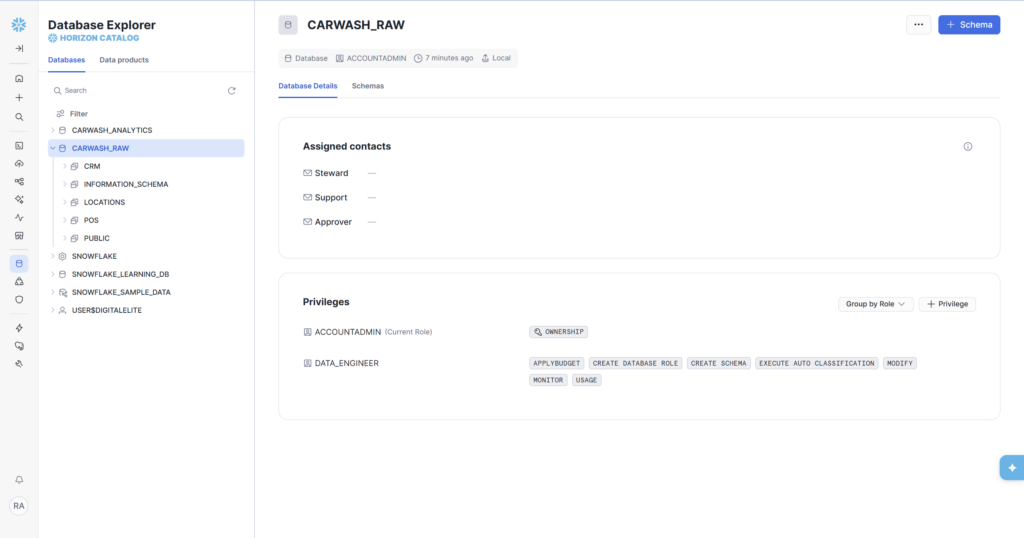
- CARWASH_RAW — Raw database with POS, CRM, LOCATIONS schemas
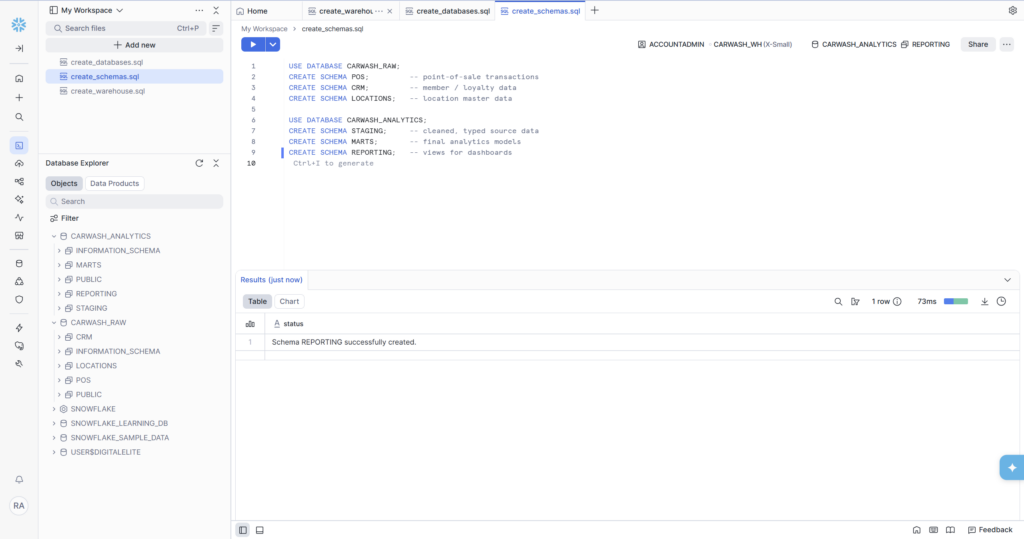
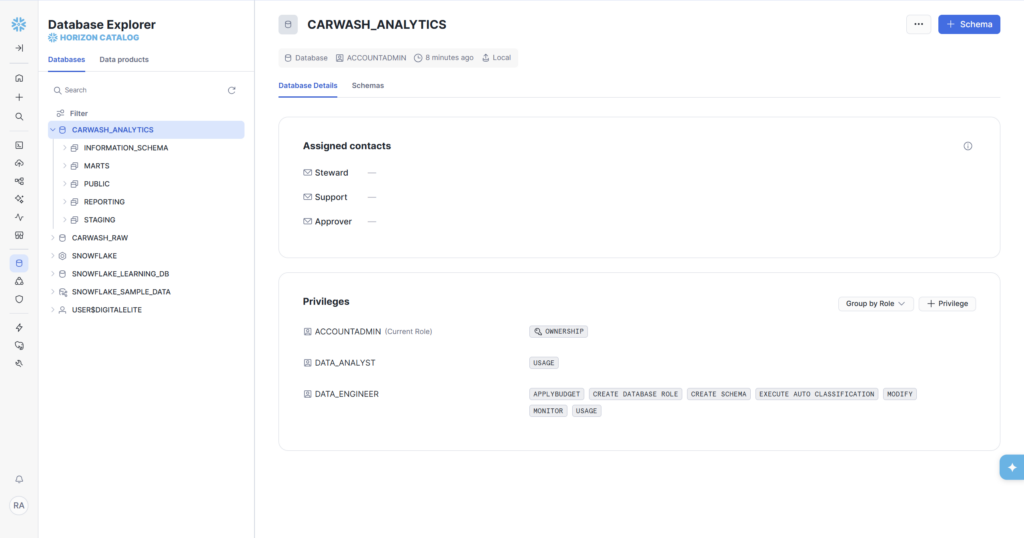
- CARWASH_ANALYTICS — Analytics database with STAGING, MARTS, REPORTING schemas
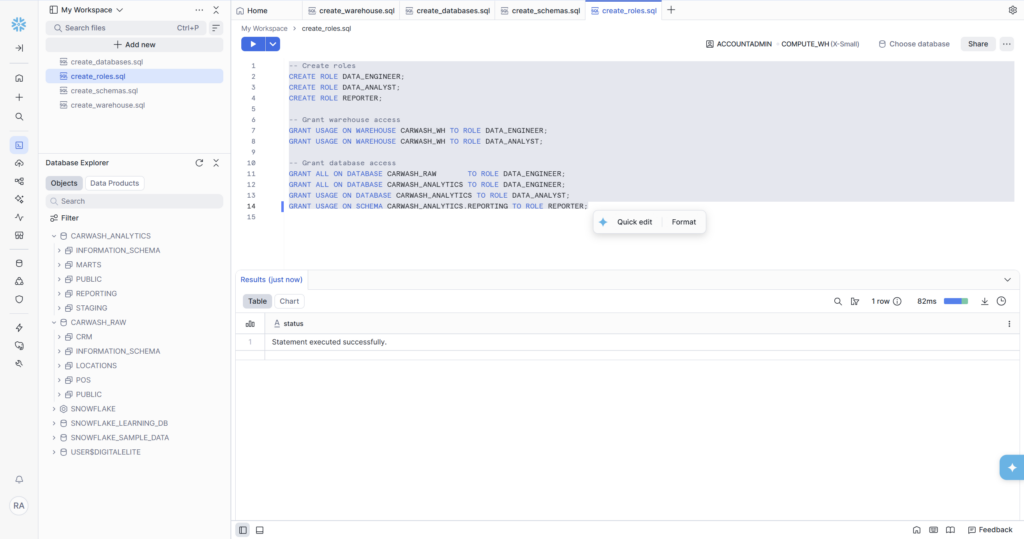
- DATA_ENGINEER role — full access to both databases
- DATA_ANALYST role — read access to CARWASH_ANALYTICS
- REPORTER role — scoped to REPORTING schema only
• SQL files saved in Snowsight workspace (create_warehouse.sql, create_databases.sql, create_schemas.sql, create_roles.sql)
What’s Coming in Phase 2
Now that the environment is ready, Phase 2 is all about table design. We’ll create the five core tables that model a real car wash business:
- LOCATIONS — where each car wash site is
- MEMBERSHIP_PLANS — the BASIC, DELUXE, and ULTIMATE wash tiers with pricing
- MEMBERS — customer records with enrollment date, plan, and status
- VISITS — every car wash visit, linked to a member and location
- TRANSACTIONS — billing events: signups, renewals, upgrades, and chargebacks
We’ll cover dimension vs. fact table design, Snowflake data types, and why the _loaded_at audit column you’ll see in every table is not optional in a real pipeline.
📁 GitHub Repo
All SQL from this series is available on GitHub at github.com/aucampr/snowflake-carwash-analytics. The Phase 1 scripts are in the /setup folder. Star the repo to follow along.
Follow Along
This is part of a 6-phase series building a complete Snowflake analytics data warehouse — from blank account to live KPI dashboards — using a car wash membership dataset. Each phase ships as a blog post, and a LinkedIn post.