Designing the Car Wash Data Model in Snowflake
Before you load a single row of data, you need to answer one question: what shape should this data be in? In Phase 2 of this series, I designed and created the five tables that form the backbone of a car wash membership analytics system — and explained the thinking behind every decision.
Quick Recap — Where We Are
In Phase 1, we built the Snowflake environment: one warehouse (CARWASH_WH), two databases (CARWASH_RAW and CARWASH_ANALYTICS), six schemas, and three roles with appropriate access controls. If you missed it, the Phase 1 post covers all of that.
Phase 2 is about schema design — the structure your data will live in. This is where most data projects succeed or fail. Get the model right now and everything downstream is easier: queries are simpler, transformations are predictable, dashboards are fast. Get it wrong and you’ll be fighting your own data forever.
 What You’ll Learn in This Post
What You’ll Learn in This Post
The difference between dimension and fact tables — with a car wash analogy. Which Snowflake data types to use and why. What the _loaded_at audit column is and why it belongs in every table. The full DDL for all 5 tables, with line-by-line explanation.
The Concept You Need First: Dimensions vs. Facts
If you’ve never built a data model before, this is the single most important concept to understand. Every analytics data model is built from two types of tables, and confusing them is the most common beginner mistake.
Dimensions: The WHO, WHAT, and WHERE
A dimension table describes a thing. It answers: who is involved? what is it? where is it?
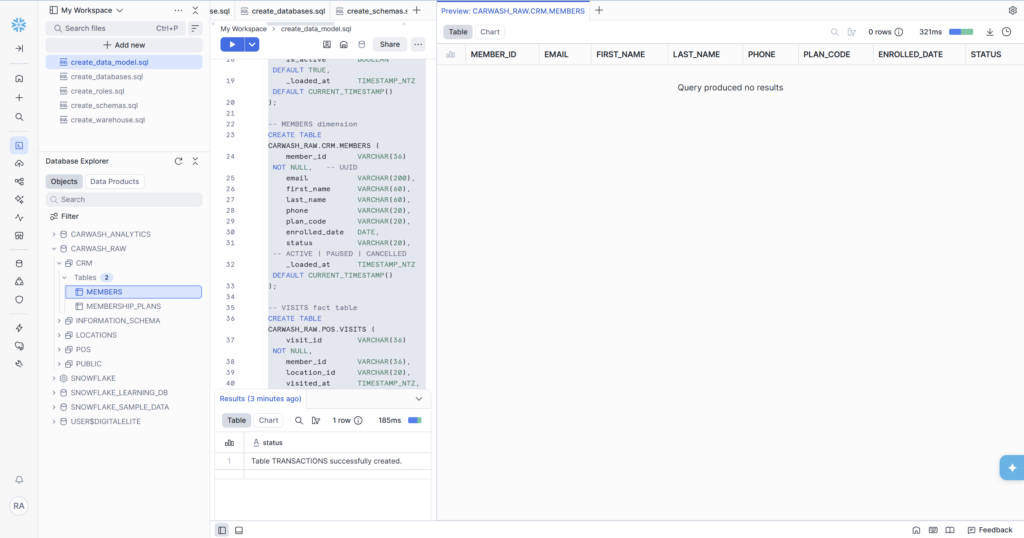
- MEMBERS is a dimension — it describes a customer: their name, email, plan, and status
- LOCATIONS is a dimension — it describes a physical site: city, state, when it opened
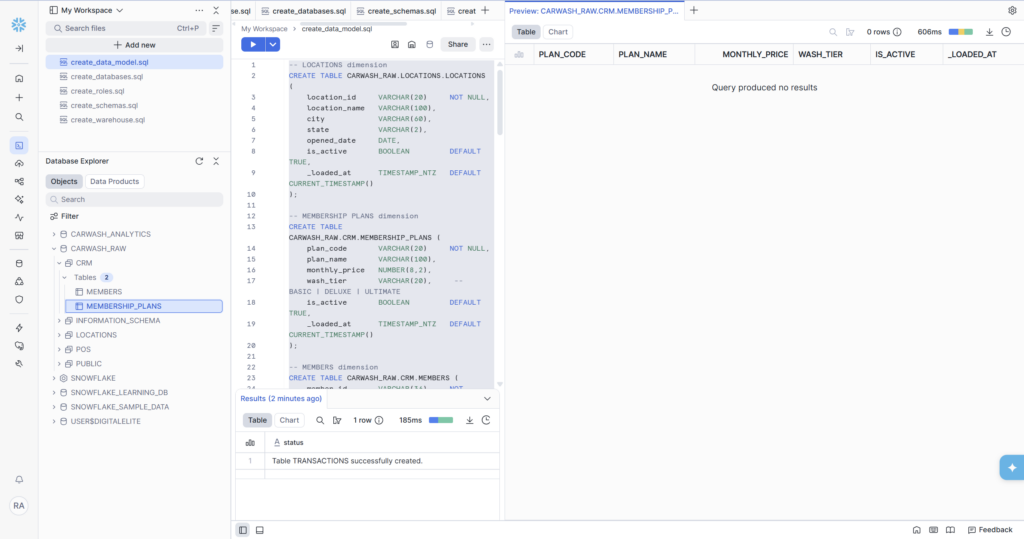
- MEMBERSHIP_PLANS is a dimension — it describes a product: the plan name, price, tier
Dimension tables change slowly. A member’s name doesn’t change every day. A location doesn’t move. A plan price might update quarterly. These are relatively stable records.
Facts: The WHAT HAPPENED
A fact table records an event. It answers: what happened, when, and who was involved?
- VISITS is a fact — it records that member X visited location Y at timestamp Z
- TRANSACTIONS is a fact — it records that member X paid $24.99 for a renewal on date Z
Fact tables grow continuously. Every day, hundreds of new visits and transactions get added. They’re typically much larger than dimension tables, and they reference dimensions by ID rather than storing the full details.
 The Car Wash Analogy
The Car Wash Analogy
Think of it this way: a MEMBER is a dimension — they have a membership card with their details on it. A VISIT is a fact — the gate records every time that card scans. The membership card (dimension) changes rarely. The scan log (fact) grows every single day. When you want to answer ‘how often does each member visit?’, you join the fact table to the dimension table on member_id.
| Table | Type | Database.Schema | Represents |
| LOCATIONS | Dimension | CARWASH_RAW.LOCATIONS | Where each car wash site is |
| MEMBERSHIP_PLANS | Dimension | CARWASH_RAW.CRM | BASIC / DELUXE / ULTIMATE tiers + pricing |
| MEMBERS | Dimension | CARWASH_RAW.CRM | Customer records, plan, enrollment, status |
| VISITS | Fact | CARWASH_RAW.POS | Every car wash visit — linked to member + location |
| TRANSACTIONS | Fact | CARWASH_RAW.POS | Billing events: signups, renewals, upgrades |
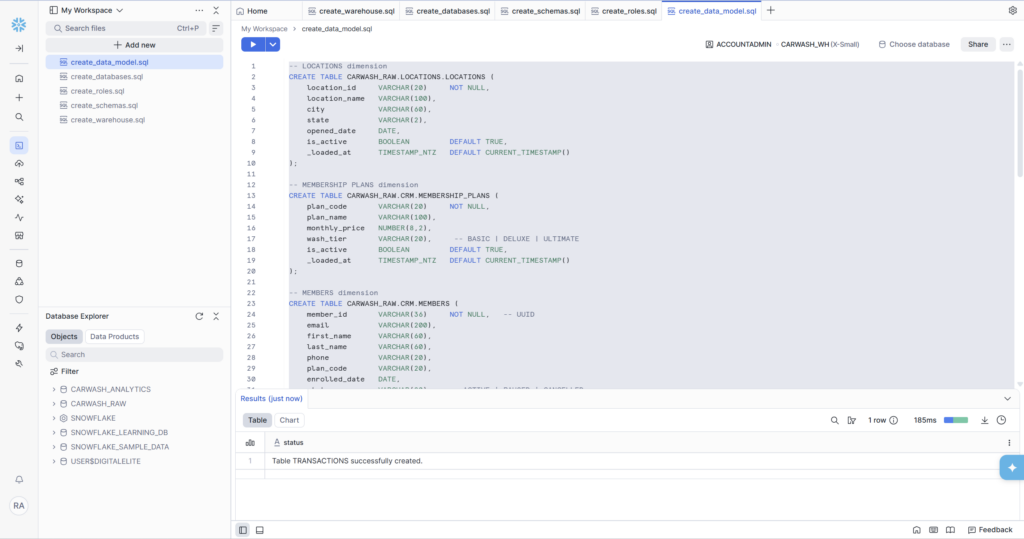
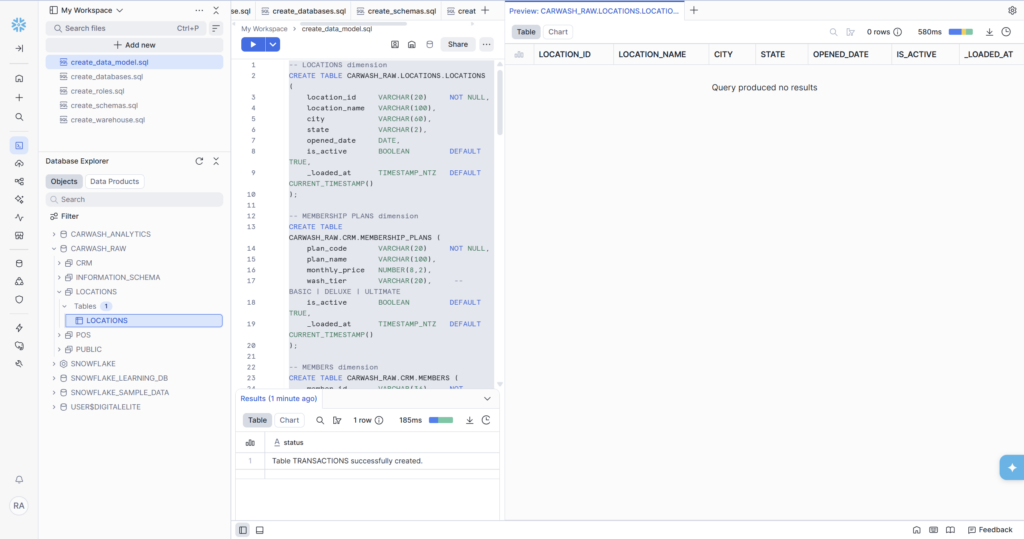
Table 1: LOCATIONS (Dimension)
The simplest table in the model. One row per physical car wash location. This is reference data — it changes rarely and is used to enrich visit and transaction records with human-readable location names and geographic data.
A few decisions worth explaining here:
- state is VARCHAR(2) — not VARCHAR(50). We only need the two-letter abbreviation (IN, OH, MN). Using the tightest possible type is good practice: it prevents someone from accidentally storing ‘Indiana’ in a field meant for ‘IN’, which would break joins later.
- is_active BOOLEAN DEFAULT TRUE — when we add a new location, it’s active by default. If it closes, we flip this to FALSE rather than deleting the row. Deleting dimension records breaks historical data.
- _loaded_at TIMESTAMP_NTZ — the underscore prefix is a convention for audit/system columns. NTZ means ‘no timezone’ — all timestamps in this system are stored in UTC.